Notice technique de la spécialisation en DITA
Introduction
La spécialisation est une des caractéristiques essentielles de la DITA. Bien que nous ne l'ayons pas utilisée dans ce projet, une partie de l'état de l'art y a été consacrée. Cette notice a pour but de résumer l'intérêt et les mécanismes de spécialisation en DITA.
Spécialisation de type
Les types de base de DITA ne sont pas toujours suffisants (trop généraux) pour la documentation technique, mais il existe un mécanisme de spécialisation[1] qui repose fortement sur la notion d'héritage. Cela permet d'intégrer des éléments spécifiques tels que des procédures d'urgence ou des plans, qui peuvent faire l'objet de transformations spécifiques pour un affichage approprié. Cependant la force de la spécialisation est qu'un moteur de transformation prévu pour les éléments de base permettra quand même l'affichage des éléments spécifiques, en les affichant de la même manière que les éléments dont ils dérivent. Cette caractéristique est particulièrement intéressante dans le cas d'échange de contenus spécialisés entre deux sociétés/organismes utilisant le standard DITA (et n'ayant pas nécessairement connaissance des spécialisations de l'autre). De plus, on a la possibilité, grâce au renommage des balises, d'avoir un langage typé métier.
Spécialisation de domaine
Il ne semble pas que nous ayons besoin de la spécialisation de domaine.
Spécialisation de topic : concept, task et reference
Pour bien comprendre comment fonctionne la spécialisation, il est à noter que concept, task et reference sont des spécialisations de topic. Cela est illustré par le schéma suivant :
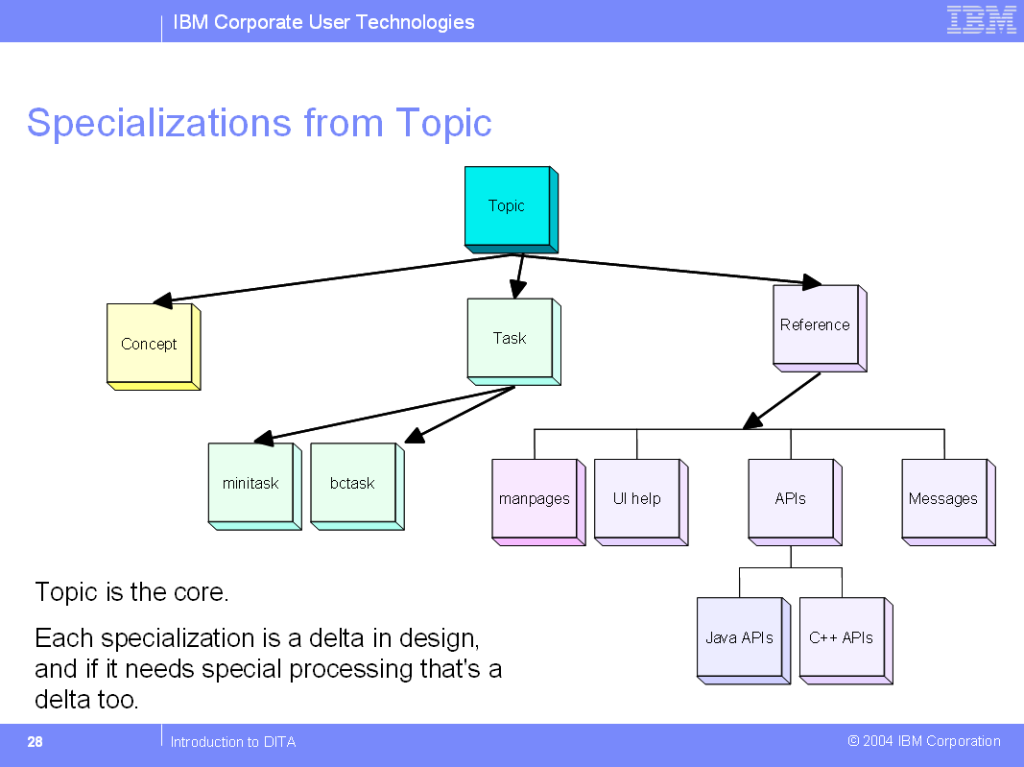
(source :http://www.xml.gov/documents/completed/ibm/dita.ppt)
Cela signifie qu'une nouvelle DTD a été créée : concept.dtd par exemple.
Celle-ci reprend des éléments de topic.dtd de cette manière :
<!-- Embed topic to get generic elements -->
<!ENTITY % topic-type PUBLIC
"-//OASIS//ELEMENTS DITA 1.2 Topic//EN"
"/base/dtd/topic.mod">
%topic-type;
Et d'autre part redéfinit ses propres éléments de cette manière :
<!-- Embed concept to get specific elements -->
<!ENTITY % concept-typemod
PUBLIC
"-//OASIS//ELEMENTS DITA 1.2 Concept//EN"
"concept.mod">
%concept-typemod;
C'est donc au sein de concept.mod que seront spécifiés les éléments et leur cardinalité. Pour chaque topic, il faut en effet au sein de DITA une DTD à laquelle sont liés des .mod (définition des éléments) et un .ent (déclaration des entités utilisées). De plus des % sont utilisés comme références (en fait les éléments références référencent des éléments du même nom).
Enfin, étant donné qu'on a renommé des éléments existants, il faut à l'aide de class faire le lien entre l'élément déjà existant (père, e.g. body) et celui qu'on vient de redéfinir (fils, e.g. conbody)
de cette manière :
<!ATTLIST concept %global-atts; class CDATA "- topic/topic concept/concept ">
<!ATTLIST conbody %global-atts; class CDATA "- topic/body concept/conbody ">
C'est ce mécanisme qui permet d'utiliser une transformation définie pour le type général sur le type spécialisé.
Une fois toutes les spécialisations définies au sein des nouvelles DTD, on se retrouve avec les configurations suivantes :
Concept topic :
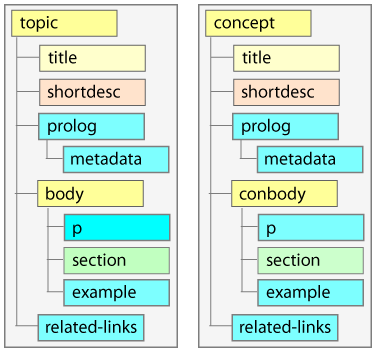
Task topic :

Reference topic :
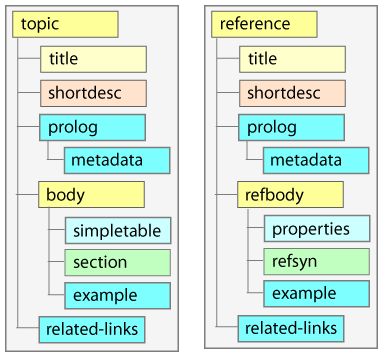
On peut alors appliquer ou non un XSL spécifique sur les éléments spécifiques. On peut également de la même manière aller plus loin et spécialiser Concept, Task ou Reference.
(source des images : http://www.ditausers.org/training/DITATopics/ )
Créer sa propre spécialisation : outils
La création de documents DITA et de spécialisations nécessite à la fois un éditeur XML, un outil pour vérifier que les documents XML sont valides par rapport à la DTD créée, ainsi qu'un moteur de transformation de la DITA vers d'autres support (PDF, web). Oxygen répond à l'ensemble de ces besoins.
Créer sa propre spécialisation : règles
Lorsqu'on spécialise un type déjà existant, on peut :
reprendre tout ou partie des éléments du type,
renommer éventuellement les éléments repris,
restreindre éventuellement les cardinalités des éléments repris.
En revanche, on ne peut pas ajouter de nouveaux éléments : la spécialisation est restrictive.
Le changement de cardinalité répond aux règles suivantes :
un élément "unique et requis" doit être conservé,
un élément "optional" peut rester "optional", devenir "unique et requis" ou être supprimé,
un élément "one or more" peut rester "one or more", devenir "unique et requis" ou séparé en éléments renommés (exemple : a+ peut devenir a1, a2+, a3?, a4*, mais pas a1? qui est moins restrictif),
un élément "zero or more" suit les mêmes règles qu'un élément "one or more" et peut aussi devenir "optional" ou être supprimé,
un choix de plusieurs éléments (exemple a | b) peut devenir un choix partiel de ces éléments,
dans tous les cas précédents, l'élément peut toujours être renommé.
Créer sa propre spécialisation : exemple
Pour créer sa propre spécialisation il faut commencer par un travail d'analyse sur le corpus et une prise de connaissance de la DITA pour identifier à quel élément de base on peut se rapporter le plus. Par exemple s'agit-il plutôt d'un topic ? d'un concept ? d'une reference ? d'une task ? Afin de tester comment marche techniquement la spécialisation, on peut par exemple vouloir créer un contenu de type introduction, avec juste un titre et du texte, l'élément qu'on va alors utiliser est un topic. A noter que cet exemple n'est pas pertinent dans un contexte de production mais facile à comprendre.
Une fois qu'on a identifié l'élément qui fournit la meilleure base pour notre spécialisation, il faut commencer par créer du contenu en DITA en utilisant le dit élément. Dans notre cas nous créons donc une map, contenant divers topicref vers des éléments et en particulier un topic (l'introduction) qui comporte un title et un body contenant lui même des p. Dans la pratique il est recommandé de produire un nombre suffisamment significatif d'exemples de contenus afin de pouvoir bien identifier toute la variabilité dès le début et ainsi faire une spécialisation efficace. Si le contenu a été bien écrit on doit pouvoir transformer la map en un document PDF par exemple à l'aide d'Oxygen (gestionnaire de cartes DITA).
Il faut ensuite passer à l'étape de spécialisation. On commence par créer une DTD correspondante qu'on associe avec le fichier DITA en question.
Dans notre exemple on veut spécialiser topic. Comme concept est une également spécialisation de topic et que l'on se limite à des éléments basiques (title et body) présents dans concept le plus simple est de modifier la DTD de concept selon nos besoins. Si l'on voulait spécialiser task on procéderait de la même manière en reprenant la DTD de task.
On commence par changer les noms des attributs. Dans notre exemple on choisit intro pour la racine et introbody pour le corps. Puis on se restreint aux éléments dont on a besoin. Par exemple
<!ENTITY % intro.content
"((%title;),
(%titlealts;)?,
(%abstract; |
%shortdesc;)?,
(%prolog;)?,
(%introbody;)?,
(%related-links;)?,
(%intro-info-types;)* )"
>
devient
<!ENTITY % intro.content
"((%title;),
(%introbody;)? )"
>
en respectant la règle selon laquelle on ne peut que être que plus restrictif lorsque l'on spécialise un élément. (voir )
De cette manière, on définit l'ensemble des éléments dont on a besoin au sein du .mod
Une fois les éléments définis avec les cardinalités adéquates il faut spécifier le lien d'héritage des différents éléments de cette manière :
<!ATTLIST intro %global-atts; class CDATA "- topic/topic intro/intro ">
<!ATTLIST introbody %global-atts; class CDATA "- topic/body intro/introbody ">
Cela signifie que intro est une spécialisation de topic et introbody une spécialisation de body.
Il est important lors de la création de la DTD de procéder de manière itérative. En particulier il faut prendre le soin de vérifier régulièrement que le .dita est toujours valide par rapport à la DTD et que la transformation de la map DITA en PDF par exemple fonctionne bien. En effet, Oxygen ne comporte pas de debugger lorsque la génération échoue et il devient donc très difficile de trouver la source de l'erreur si l'on a tout édité d'un coup.
Cas des images : imagemap
L'exemple d'une image à laquelle on puisse associer des commentaires par zone a été évoqué lors de la séance du 30 novembre. La question était de savoir si DITA permettait de faire quelque chose de similaire à l'exemple suivant (tiré de ce qu'on peut faire avec la chaîne éditoriale Dokiel) :
<image href="...">
<zone id="..." x="..." y="..." width="..." height="...">
<p>un commentaire sur cette zone</p>
<p>un autre commentaire</p>
</zone>
<zone id="..." ...>
<p>...</p>
</zone>
</image>
Element imagemap dans DITA
Dans la référence de la DITA, il existe un élément nommé "ditamap", qui est utilisable au sein du "body" d'un "topic" et suit la structure suivante :
<imagemap>
<image href="...">
<area>
<shape>rect</shape>
<cords>0, 0, 100, 100</cords>
<xref href="..."></xref>
</area>
<area>
...
</area>
<image>
</imagemap>
Observations
Dans ce cas, il est impossible de spécialiser imagemap en "image" : en effet, l'élément "xref", qui est une url vers un fichier DITA externe, ne peut pas être changé en "p", qui lui correspond à un commentaire interne.
En revanche, l'idée serait de conserver le type "image" en entrée (dans l'éditeur Scenari) puis appliquer deux feuilles de transformation XSL pour obtenir un imagemap en sortie :
une première pour générer le "squelette" de l'imagemap, c'est-à-dire tout, sans s'occuper des éléments "p" de commentaires (en générant néanmoins des url pour les "xref"),
une seconde pour générer des fichiers DITA externalisés pour chaque ensemble de commentaires (les noms des fichiers doivent correspondre avec les noms des "xref" générés avec la première transformation).
Ainsi, le contenu, saisi en tant qu'"image" sera transformé en un imagemap DITA qui pourra lui-même être transformé via les publications standards de DITA (PDF, HTML).

