Correcteurs automatiques et relecture de forme
La relecture de forme, telle que nous l'avons vue en révision professionnelle, peut paraître en contradiction avec l'usage aujourd'hui largement répandu des correcteurs automatiques, dont les capacités de détection et de correction d'erreurs sont croissantes. À titre d'exemple, voici le genre d'erreurs que ProLexis est capable de traiter :

Avant même l'arrivée de ces logiciels de dernière génération, la profession des correcteurs s'inquiétait de voir ce métier disparaître (voir par exemple (Brissaud, 1998[1])). Loin d'imaginer que le progrès technologique permette à terme le remplacement définitif du correcteur humain, nous pensons que chaque étape de ce progrès peut être vue comme une occasion de réaffirmer la valeur ajoutée de sa relecture compte tenu de ce que le correcteur automatique ne peut toujours pas traiter. Ainsi, la relecture humaine est toujours nécessaire pour certains faux positifs (mots ambigus typiquement) qui ne sont pas détectés avec les correcteurs standards, signe que les recherches dans ce domaine ne sont pas encore arrivées à une maturité suffisante pour faire l'objet d'une industrialisation (excepté dans certains logiciels de pointe tel que ProLexis). De plus, il nous paraît essentiel qu'un correcteur humain puisse conserver une posture critique vis-à-vis des corrections proposées par un logiciel, y compris les corrections très détaillées de l'illustration ci-dessus : par exemple, si le mot "solutionner" est indiqué comme "emploi critiqué" (d'après le Wiktionnaire, ce verbe est rejeté par de nombreux professeurs de français), il appartient au relecteur de juger si cet emploi est légitime dans le contexte éditorial visé. Enfin, la compétence d'un relecteur en matière d'ajustements stylistiques (homogénéisation, allègement...) nous semble encore supérieure à ce qui peut être traité grâce à l'analyse automatique du discours, dont les applications industrielles sont pour le moment confinées à des domaines bien précis (rédaction de cahiers des charges, de manuels techniques...).
Afin de mieux outiller le relecteur dans la recherche d'erreurs non-détectées par un correcteur automatique, une solution pourrait être de proposer un mode d'affichage aléatoire des phrases du document. Cette solution s'inspire de la technique dite de relecture "à l'envers" évoquée plus haut, qui permet de se détacher du fond pour ne se concentrer que sur la forme. De la même manière, cet affichage aléatoire permettrait de traiter les phrases hors de leur contexte et sans logique d'enchaînement entre elles :
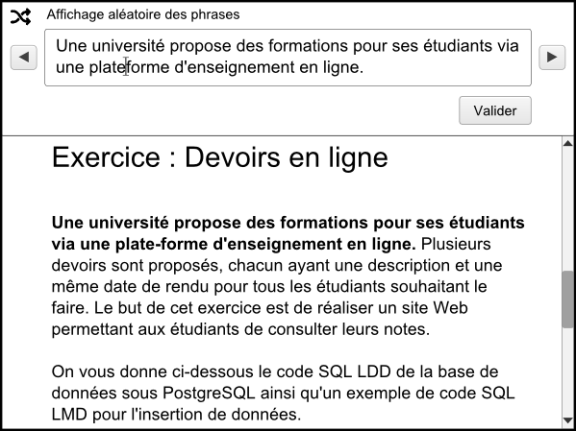
Dans la maquette ci-dessus, le relecteur peut passer les phrases une à une à l'aide de boutons précédant/suivant, proposer une correction de la phrase en éditant le champ (par exemple, changer "plate-forme" en "plateforme"), et si besoin visualiser la phrase dans son contexte (phrase mise en surbrillance dans le texte). Notons que la correction pourrait aussi être proposée dans une annotation (et non directement intégrée au contenu), typiquement dans le cas où elle doit être validée par un autre auteur.
Pour terminer ce panorama sur la question de la relecture de forme, citons brièvement le cas des documents numérisés par des techniques d'OCR (optical character recognition). Ces documents peuvent contenir plus ou moins de fautes en fonction de la qualité de la reconnaissance des caractères par la machine et/ou de la qualité des documents préservés. Kukich (1992[2]) souligne que les erreurs générées par la numérisation ne suivent pas les mêmes schémas que les erreurs humaines (par exemple, des lettres telles que "o" et "d" sont confondues à cause de leur forme similaire dans certaines écritures graphiques). Si certaines erreurs peuvent être traitées facilement à l'aide d'une approche probabiliste (typiquement, un trigramme de lettres dont la probabilité est nulle), d'autres sont plus inattendues et varient significativement en fonction du document, ce qui constitue une limite à une correction automatique complète.
Dans le cadre du projet Ozalid, la plateforme Correct (Josse, 2014[3]) a été développée pour expérimenter la correction collaborative des livres numérisés de la bibliothèque Gallica (BNF). L'interface de correction propose notamment un mode "ligne à ligne" pour une comparaison fine du texte obtenu par OCR avec l'image originale :

La vérification des corrections effectuées sur cette plateforme constitue une nouvelle problématique de relecture : typiquement, un utilisateur peut avoir corrigé un document différemment qu'un autre utilisateur, ou bien avoir corrigé une erreur qui n'en était pas réellement une (lorsque le livre a été écrit dans une vieille orthographe par exemple...), etc.. Un protocole de qualification automatique de ces corrections collaboratives, basé sur des indicateurs sémiotiques et sémantiques, a été proposé dans (Lagarrigue et al., 2014[4]).