Scenari
La suite logicielle Scenari est constituée de deux environnements principaux :
SCENARIchain pour l'édition suivant les principes d'une chaîne éditoriale (WYSIWYM, publication multi-supports, fragmentation, réutilisabilité, etc.) ;
SCENARIbuilder pour la conception d'un modèle documentaire visant à être installé et utilisé dans SCENARIchain.
Un modèle documentaire correspond à l'ensemble des ressources informatiques mobilisées par une chaîne éditoriale, à savoir :
des schémas XML contrôlant la structure des fragments (fichiers XML) que l'auteur peut instancier ;
des transformations XSL qui, appliquées aux fragments, permettent la publication de documents au format HTML, PDF, etc..
Édition et gestion
Dans SCENARIchain, la production documentaire est organisée en ateliers. Chaque atelier instancie un modèle documentaire et dispose de fonctionnalités d'édition (via un éditeur WYSIWYM, spécialisé en fonction du modèle) et de gestion (arbre de classement, recherche, réseau de fragments...). SCENARIchain peut être utilisé en local ou bien en mode client-serveur. Depuis la version 4 de Scenari, un mode de stockage des fragments s'appuyant sur une base de données permet notamment d'instrumenter des fonctions collaboratives, entre autres :
la gestion du cycle de vie des fragments ("brouillon", "à valider", "validé"...) ;
l'ajout de calques (Arribe, 2014[1]) aux ateliers afin de permettre de modifier des fragments de façon temporaire (modifications vouées à être réintégrées à l'atelier d'origine) ou définitive (dérivation des fragments pour un autre contexte de diffusion) ;
l'historique des modifications d'un fragment.
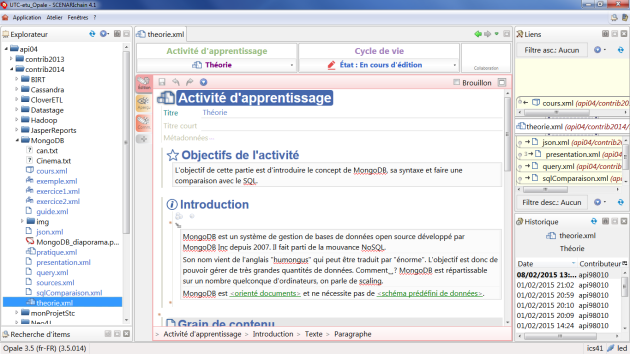
L'écran ci-dessus est composé de trois zones principales :
à gauche, l'arbre de classement ;
au centre, l'éditeur WYSIWYM d'un fragment, avec la gestion de son cycle de vie en haut ;
à droite, les liens ascendants et descendants (en haut) ainsi que l'historique (en bas) de ce fragment.
Publication et prévisualisation
Dans un modèle documentaire, les transformations sont définies au niveau de certains types de fragment appelés racines de publication. Un document publié est un fichier ou ensemble de fichiers, prêt à être diffusé sur un serveur FTP, envoyé par mail, etc.. La transformation peut également être exécutée dynamiquement (pendant le processus d'écriture par exemple), afin de prévisualiser le document dans une mise en forme proche du résultat de la publication. À travers un système de commentaires lié aux sources XML, il est possible de faire annoter (par un relecteur typiquement) les contenus depuis la prévisualisation, et de retrouver ces annotations dans les fragments au niveau de l'éditeur (notons que les annotations sont expurgées des publications classiques) :
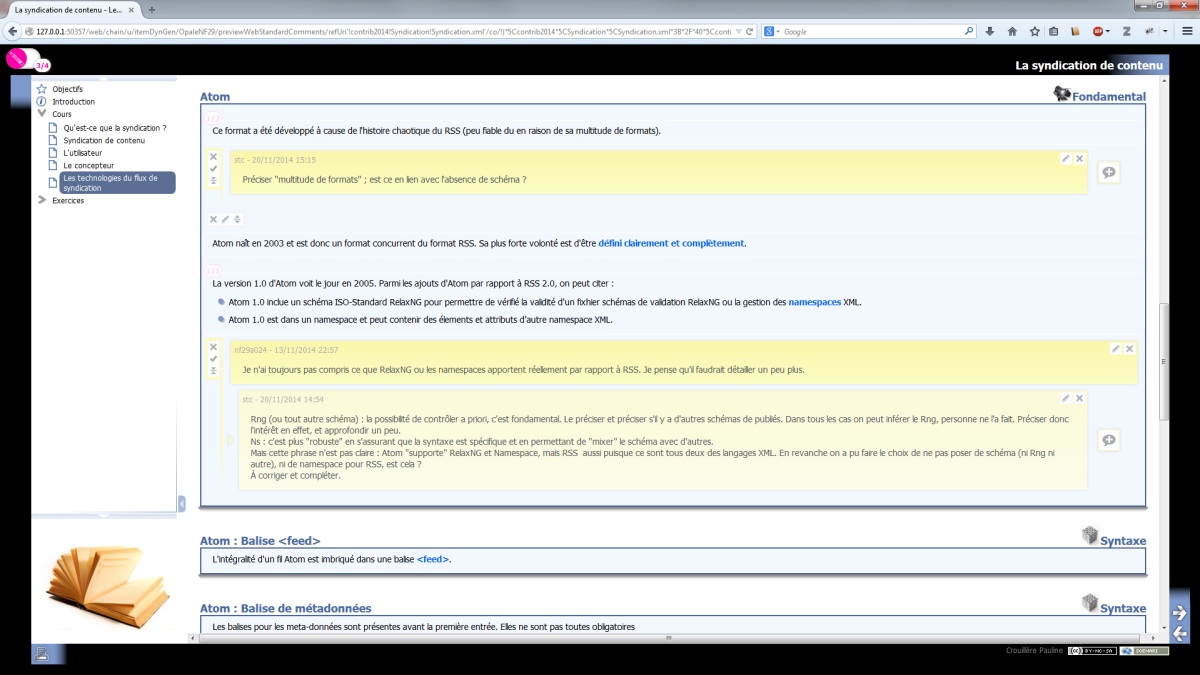
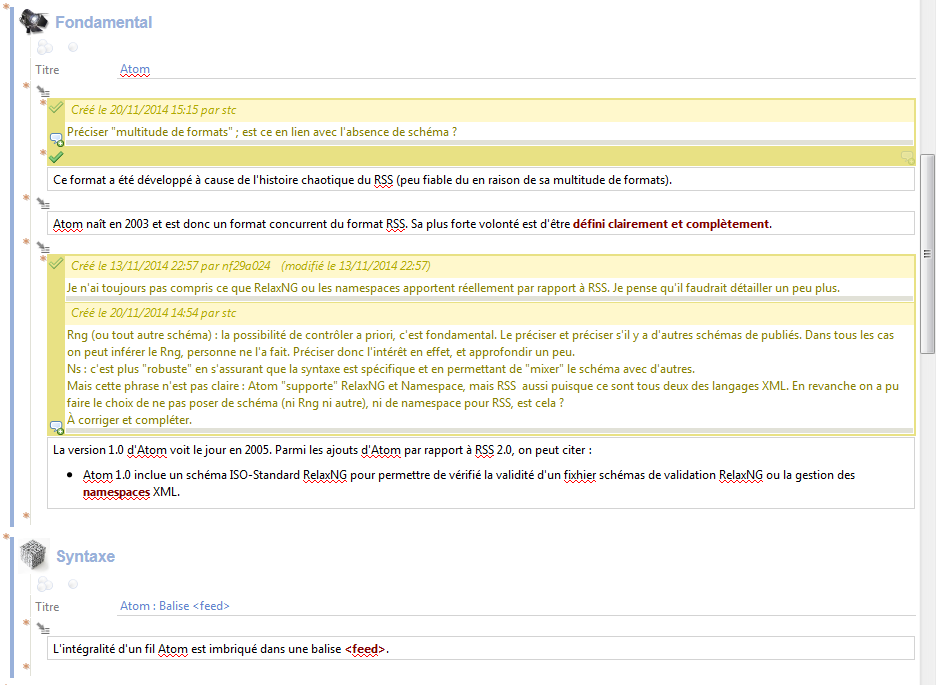
Dans la suite de cette section, nous présenterons les modèles documentaires Opale et Topaze, qui seront mobilisés comme exemples tout au long de ce mémoire.