Les chaînes éditoriales : technologie de rééditorialisation documentaire
Définition
Les chaînes éditoriales numériques sont des outils qui accompagnent la production documentaire de masse. Pour y parvenir, elles s'appuient sur une mise en évidence des structures documentaires présentes dans un corpus. Ces structures sont représentées dans un modèle documentaire qui contrôle la validité des documents. La publication des documents s'opère par des algorithmes de transformation qui s'appuient sur le modèle pour publier des documents dans des formats standards comme PDF ou HTML.
En travaillant uniquement sur des structures et en automatisant la mise en forme, les chaînes éditoriales permettent la séparation entre le fond et la forme - ou entre le fonds documentaire et ses formes (Bachimont & Crozat, 2004[1]). Elles facilitent ainsi une automatisation des manipulations documentaires.
Les documents numériques contrôlés par un modèle documentaire sont appelés des documents structurés (André, Futura & Quint, 1989[2]). Leur édition ne s'opère plus en fonction de la transformation de restitution proposée dès l'édition, soit selon le paradigme WYSIWYG (What You See Is What You Get), mais selon la sémantique des structures proposées, soit selon le paradigme WYSIWYM (What You See Is What You Mean) (Crozat, 2007[3], p. VI).
Sur le plan technologique, les chaînes éditoriales s'appuient sur les technologies de marquages que sont le SGML et son successeur le XML. Les briques technologiques élémentaires sont donc :
Exemple : chaîne éditoriale pour l'écriture et la publication d'un dictionnaire
Prenons l'exemple d'une chaîne éditoriale minimale pour l'édition d'un dictionnaire. Les structures qui composent un dictionnaire sont très semblables les unes aux autres. Elles comprennent le nom d'un terme, sa qualification grammaticale ainsi qu'une ou plusieurs définitions. Ces structures sont formalisées dans le schéma suivant exprimé dans le standard RelaxNG.
<element name="dictionnaire" xmlns="http://relaxng.org/ns/structure/1.0">
<attribute name="titre"/>
<oneOrMore><element name="entree">
<element name="terme">
<text/> </element><element name="qualifGram">
<text/> </element> <oneOrMore><element name="definition">
<text/> </element> </oneOrMore> </element> </oneOrMore></element>À partir de ce schéma, un éditeur XML permet l'édition de dictionnaires. L'exemple ci-dessous est un dictionnaire contenant deux définitions.
<dictionnaire titre="Le Petit Nibbler">
<entree><terme>Rééditorialisation</terme>
<qualifGram>Nom féminin</qualifGram>
<definition>Le terme de rééditorialisation est un néologisme qui a émergé dans le domaine du document numérique pour désigner le processus consistant à reconstruire un nouveau document à partir d'archives. La construction de ce mot tente une première synthèse entre les concepts d'édition au sens de publication d'une œuvre, d'éditorialisation au sens d'expression d'un point de vue propre, de réédition au sens de nouvelle proposition de lecture. Elle tente une seconde synthèse entre les fonctions d'éditeur, celui qui met en forme et diffuse, et d'auteur, celui qui écrit, fonctions qui tendent à se mêler dans le contexte du numérique. La rééditorialisation est donc la publication d'une œuvre originale dans son point de vue, sa forme, sa scénarisation, à partir de contenus qui ne le sont pas tous.</definition>
</entree> <entree><terme>Redocumentarisation</terme>
<qualifGram>Nom féminin</qualifGram>
<definition>Désigne à la fois un retour sur une documentarisation ancienne et une révolution documentaire. (Pédauque)</definition>
<definition>Processus de transfert de documents existants sur le support numérique pour leur permettre de nouvelles manipulations. (Salaun)</definition>
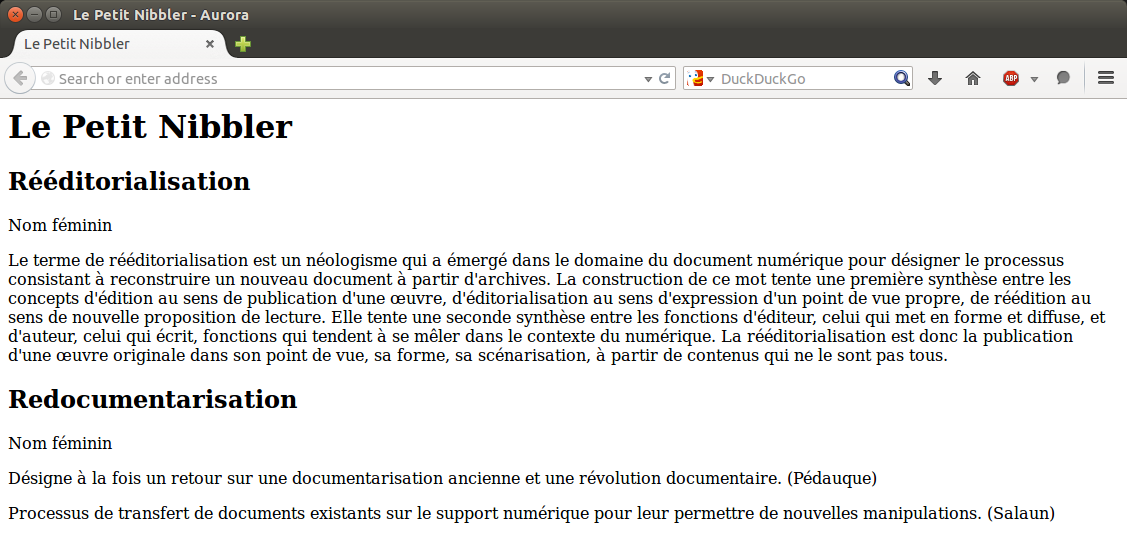
</entree></dictionnaire>Un algorithme de transformation permet ensuite de transformer un dictionnaire ainsi formé en un document encodé dans un format standard. L'exemple ci-dessous transforme le dictionnaire XML en document HTML. Le rendu HTML affiché par un navigateur est illustré dans la figure 6.
Transformation
12<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema" exclude-result-prefixes="xs" version="1.0">
3<xsl:output method="html" encoding="UTF-8"/>
4<xsl:template match="/">
5<html>6<head><title><xsl:value-of select="dictionnaire/@titre"/></title></head>
7<body>8<h1><xsl:value-of select="dictionnaire/@titre"/></h1>
9<xsl:apply-templates/>10</body>11</html>12</xsl:template>1314<xsl:template match="entree">
15<h2><xsl:value-of select="terme"/></h2>
16<p class="formGram"><xsl:value-of select="qualifGram"/></p>
17<xsl:for-each select="definition">
18<p class="def"><xsl:value-of select="."/></p>
19</xsl:for-each>20</xsl:template>2122</xsl:stylesheet>Fichier HTML produit
1<html>2<head>3<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
45<title>Le Petit Nibbler</title>
6</head>7<body>8<h1>Le Petit Nibbler</h1>
910<h2>Rééditorialisation</h2>
11<p class="formGram">Nom féminin</p>
12<p class="def">Le terme de rééditorialisation est un néologisme qui a émergé dans le domaine du document numérique pour désigner le processus
13consistant à reconstruire un nouveau document à partir d'archives. La construction de ce mot tente une première synthèse entre
14les concepts d'édition au sens de publication d'une œuvre, d'éditorialisation au sens d'expression d'un point de vue propre,
15de réédition au sens de nouvelle proposition de lecture. Elle tente une seconde synthèse entre les fonctions d'éditeur, celui
16qui met en forme et diffuse, et d'auteur, celui qui écrit, fonctions qui tendent à se mêler dans le contexte du numérique.
17La rééditorialisation est donc la publication d'une œuvre originale dans son point de vue, sa forme, sa scénarisation, à partir
18de contenus qui ne le sont pas tous.
19</p>2021<h2>Redocumentarisation</h2>
22<p class="formGram">Nom féminin</p>
23<p class="def">Désigne à la fois un retour sur une documentarisation ancienne et une révolution documentaire. (Pédauque)</p>
24<p class="def">Processus de transfert de documents existants sur le support numérique pour leur permettre de nouvelles manipulations. (Salaun)</p>
2526</body>27</html>
Chaînes éditoriales et rééditorialisation
Les chaînes éditoriales disposent de deux atouts leur permettant d'être des outils adaptés pour l'expérimentation de la rééditorialisation.
Les documents qu'elles manipulent sont structurés et les structures sont conçues selon la sémantique des contenus. Cela permet de prévoir a priori des fragments de contenus pouvant être réutilisables et surchargeables. Par exemple, au sein du schéma de dictionnaire, une entrée est sémantiquement indépendante des autres tandis qu'un terme est intrinsèquement lié à ses définitions. Fragmenter et partager une entrée entre plusieurs dictionnaires est donc plus logique.
Les chaînes éditoriales assument la séparation entre le dispositif d'enregistrement et le dispositif de restitution. La rédaction des contenus s'opère dans un environnement graphique différent de la restitution (principe au cœur des environnements WYSIWYM). L'édition séparée, le référencement et la surcharge manuelle ou programmée des fragments ne constituent alors qu'une abstraction supplémentaire dans un processus d'abstraction déjà entamé.
La suite Scenari
Notre recherche est financée par la société Kelis assistée par un dispositif CIFRE. Elle s'inscrit dans le cadre industriel et technologique de la société. Kelis est l'éditeur de la suite logicielle de chaînes éditoriales Scenari (Crozat, 2007[3]).
La suite Scenari est composée :
de SCENARIbuilder, un logiciel de conception des modèles documentaires, des éditeurs XML associés et des algorithmes de transformation ;
d'un ensemble de logiciels permettant un usage de bureau ou client - serveur (SCENARIclient, SCENARIserver, SCENARIserver-lite, SCENARIchain) exploitant un modèle produit par SCENARIbuilder pour instancier un espace pour la rédaction de documents ;
de SCENARIstyler, un logiciel permettant de produire des modèles documentaires alternatifs dont le stylage des documents produits est modifié.
L'ensemble des logiciels de la suite Scenari est publié sous licence libre. Ils sont soutenus par une communauté d'utilisateurs rassemblés administrativement dans une association loi 1901 présente en ligne sur le site scenari-plateforme.org.