La modélisation des chaînes éditoriales
Les modèles de chaînes éditoriales
Les modèles de documents exploités par les chaînes éditoriales peuvent se concevoir selon deux paradigmes : ils peuvent être conçus pour s'adapter au mieux à un contexte d'usage donné, on parlera alors de modèles dédiés ; à l'inverse, ils peuvent être conçus pour gérer l'exhaustivité d'une famille de contextes, on parlera de modèles universels (Arribe, Crozat, Bachimont & Spinelli, 2012[1]).
Historiquement portées par SGML, les approches par modèles dédiés sont aujourd'hui ancrées dans les technologies XML. L'intérêt du modèle dédié est par construction son adéquation au contexte adressé. C'est la solution juste et nécessaire au problème, permettant de traiter des structures documentaires métiers comme des tableaux comptables, des scénarios pédagogiques ou encore des procédures d'intervention, sans scories héritées de fonctions liées à d'autres contextes d'usage.
Un modèle universel est au contraire un modèle à forte valeur de généralité visant à circonscrire l'ensemble des usages pour une famille de contextes éditoriaux. Généralement portés par un organisme de standardisation comme le W3C ou OASIS, les modèles universels visent l'intégration d'un très large ensemble de besoins, et misent sur la mutualisation des développements autour du standard. Les exemples les plus utilisés sont DITA (OASIS, 2010)[2] et DocBook (OASIS, 2009[3]). La raison d'être du modèle universel, une fois celui-ci standardisé et les développements associés mûris, est la possibilité de disposer de chaînes éditoriales prêtes à l'emploi.
L'enjeu des méthodes de conception de chaînes éditoriales est d'être le plus générique possible afin de permettre l'adressage d'un maximum de contextes. Par construction, la conception d'une chaîne éditoriale exploitant un modèle universel est générique. L'objectif de la modélisation des chaînes éditoriales est d'atteindre un niveau de généricité équivalent pour la conception de chaînes éditoriales exploitant des modèles dédiés.
Généricité par déclinaison ou génération
Dans son ouvrage, Cassirer (1977[4]) s'intéresse aux différentes théories de la notion de concept pour mettre en relief les notions de déclinaison et génération. Il y distingue deux approches : d'un côté la logique formelle forgée par Aristote, de l'autre celle des sciences modernes et contemporaines. L'objet de la logique formelle est l'étude de la métaphysique : « l'essence et l'articulation de l'être »
, dit autrement, ce qui est. Du côté des sciences modernes, la notion de concept ne s'appuie pas uniquement sur l'existence mais également sur la preuve, ce qui est vérifiable.
Le concept vu par la logique est « un rassemblement par similitude d'essence »
, c'est-à-dire un rassemblement d'individus par ressemblance. Par exemple, l'hirondelle, le moineau et l'aigle ont tous des plumes, des ailes et un bec. Ces caractéristiques constituent l'essence du concept d'oiseau. La généralisation d'un concept vers un concept de niveau supérieur se fait en procédant au rassemblement des concepts de niveau inférieur. Un animal serait un mammifère, un oiseau, un amphibien, un poisson ou un reptile. Le concept universel serait alors une liste de toutes les essences possibles de ce qui est. L'universalité sera ici appelée abstraite car il n'existe pas de relation entre un concept et un sous-concept. Le passage de concept au sous-concept se fait par une déclinaison de l'ensemble des propriétés du concept.
Pour Cassirer, le concept scientifique est une abstraction de la liste des propriétés, permettant ainsi la réunion de sous-concepts qui ne se ressemblent pas dans un même concept. Ces sous-concepts sont obtenus par une fonction génératrice attachée au concept. En partant du nombre 0 et avec la loi successeur, il est possible de générer l'ensemble des entiers naturels. La généralisation de plusieurs concepts scientifiques se fait en changeant les fonctions génératrices. L'universalité est ici appelée concrète car les fonctions du concept universel permettent la génération de l'ensemble des individus qui le composent.
Déclinaison en ingénierie documentaire
Le modèle DITA (OASIS, 2010[2]) est un exemple typique de modèle universel déclinable. Sa définition est relativement simple et se compose d'éléments génériques (topic, task, map, reference, concept). Un outil universel peut donc proposer l'utilisation de ces éléments et leur transformation en documentation technique. Le standard DITA inclut un système d'héritage qui permet la spécialisation d'un nouvel élément qui hérite des propriétés d'un des éléments génériques et inclut de nouvelles propriétés.
Un tel système de déclinaison permet en effet d'approcher l'universalité des usages. Néanmoins, chaque nouvelle déclinaison demande la production de code source spécifique ce qui est laborieux et onéreux. En outre, l'objectif d’interopérabilité du standard n'est que partiellement atteint. Il est bel et bien possible d'échanger des contenus entre n'importe quelle chaîne éditoriale construite autour du standard DITA mais un contenu spécialisé perdra l'ensemble de ses propriétés particulières et sera rapporté à l'élément générique dont il est issu.
L'ingénierie dirigée par les modèles
L'ingénierie logicielle apporte une théorie opérationnelle au concept de généricité par génération de Cassirer. Il s'agit de l'ingénierie dirigée par les modèles (IDM). La notion de modèle est ici à entendre selon la définition consensuelle de Rosenberg (1989[5], p. 75) : « Modeling, in the broadest sense, is the cost-effective use of something in place of something else for some cognitive purpose. It allows us to use something that is simpler, safer or cheaper than reality instead of reality for some purpose. A model represents reality for the given purpose; the model is an abstraction of reality in the sense that it cannot represent all aspects of reality. »
Un modèle est donc une vue simplifiée de quelque chose afin d'en simplifier son usage. Bézivin (2005[6]) propose d'illustrer la notion de modèle avec l'exemple de la cartographie. Une carte est effectivement une vue simplifiée permettant de montrer certaines réalités. Une carte sans simplification, soit à l'échelle 1:1 et représentant exactement un territoire, n'est d'aucune utilité.
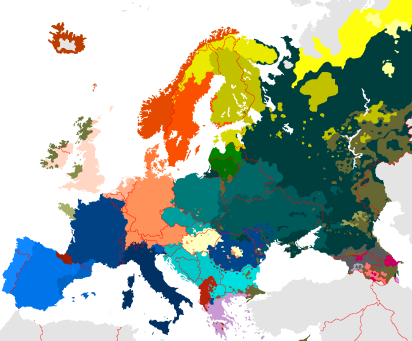
Pour dessiner et interpréter une carte, il est nécessaire d'avoir l'usage d'une légende. Sans légende, un observateur de la carte illustrée sur la figure 10 reconnaît la carte de l'Europe. Une observation attentive peut lui faire deviner que le code couleur est lié aux cultures européennes mais à moins d'être un spécialiste des données modélisées, il n'est pas possible d'aller plus loin. La légende montrée sur la figure 11 nous indique exactement le code couleur et les différentes cultures représentées sur la carte.
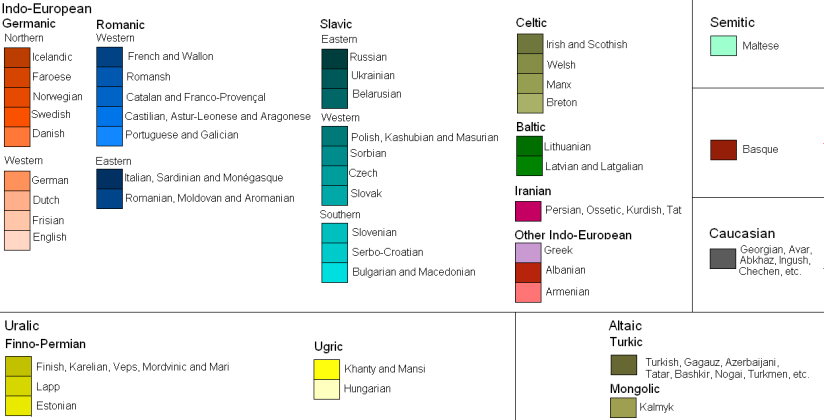
La légende est un méta-modèle de carte (ibid.[6]). En posant une unique légende, il est possible de modéliser un nombre infini de cartes à toutes sortes d'échelles ou représentant des régions différentes.
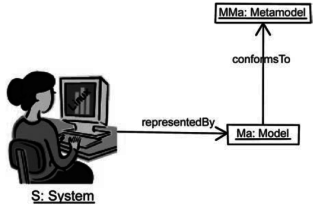
Le concept clé de l'ingénierie dirigée par les modèles consiste à mobiliser les modèles, non plus comme une simple perspective assistant à la conception, mais comme une véritable ressource opérationnelle pour la production d'un système (Brambilla, Cabot & Wimmer, 2012[7]). Ce changement dans l'usage des modèles se fait en utilisant un algorithme de transformation qui génère le système final à partir du modèle. Pour pouvoir être transformé, le modèle doit être valide. Cette validité et l'ensemble des possibles à modéliser sont définis par le méta-modèle. Algorithme de transformation et méta-modèle sont donc les deux éléments nécessaires à une approche de conception dirigée par les modèles.
Appliquée à la conception des chaînes éditoriales, la généricité préalablement visée est alors atteignable à condition de concevoir un méta-modèle permettant l'expression de l'ensemble des modèles documentaires et leurs générations ultérieures en chaîne éditoriale.
Modèle, IDM et raison computationnelle
Le passage de la modélisation sur papier à la modélisation dans un logiciel contrôlé par un méta-modèle constitue à notre sens une bonne illustration de la raison computationnelle. Outre le programme, le réseau et la couche, Bachimont (2010[8], pp. 169-171) complète l'analogie par la figure de la maquette numérique en comparaison au schéma. Les notions de modèles et d'ingénierie dirigée par les modèles sont à notre sens une généralisation de cet exemple. Le schéma est un modèle classique et la maquette numérique est un modèle manipulable et contrôlé.
SCENARIbuilder, logiciel de conception de chaînes éditoriales dirigé par les modèles
Le logiciel SCENARIbuilder s'inscrit dans le paradigme d'ingénierie dirigée par les modèles. Il permet la modélisation d'une chaîne éditoriale et la génération d'une archive de code source qui, utilisée avec SCENARIchain ou SCENARIserver, permet d'instancier une chaîne éditoriale au modèle dédié.
La modélisation s'appuie sur des primitives de documents et des primitives de transformations. Trois familles de primitives de documents sont à disposition des modélisateurs, les primitives de composition qui définissent les liens méréologiques entre un ensemble et ses parties, des primitives de métadonnées et des primitives de ressources. La combinaison de ces trois familles permet l'expression de n'importe quelle structure de document. Les primitives de transformation permettent de spécifier les algorithmes de transformation des structures documentaires valides vers des formats standards (PDF, OpenDocument, HTML).
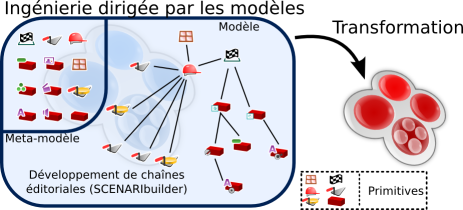
Exemple
Nous utilisons le standard UML (OMG, 2011[9]) afin de représenter un modèle Scenari. Chaque classe représente une primitive documentaire. Nous utilisons les stéréotypes pour donner le type de primitive choisie (composition, meta et ressource). L'exemple de dictionnaire de la section précédente peut être modélisé comme illustré sur la figure 14.
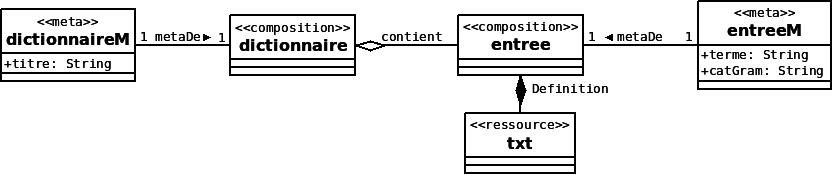
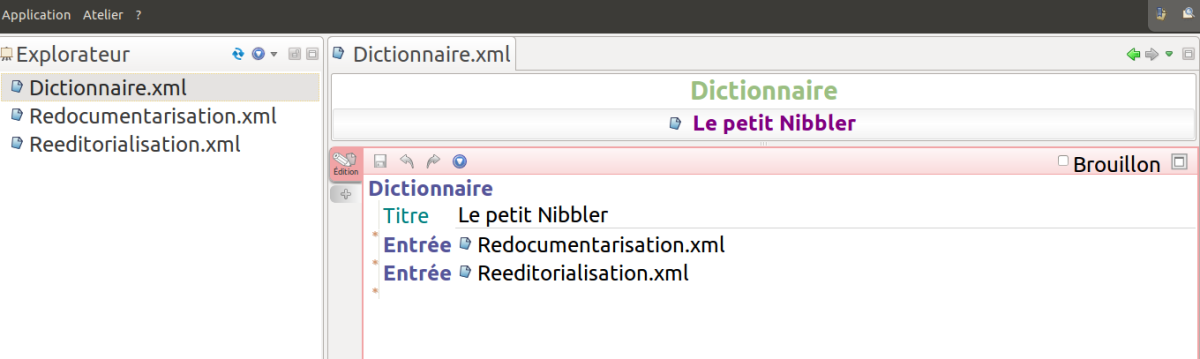
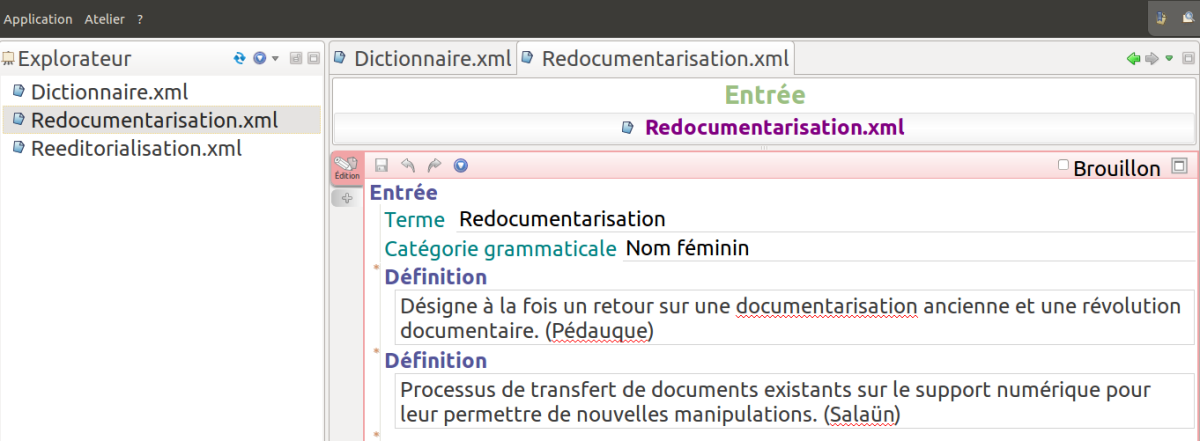
Dans cet exemple, les primitives de méta-données sont utilisées pour définir des champs de données (titre pour le dictionnaire, terme et catGram pour les entrées). Un dictionnaire référence des fragments entree qui contiennent des définitions.
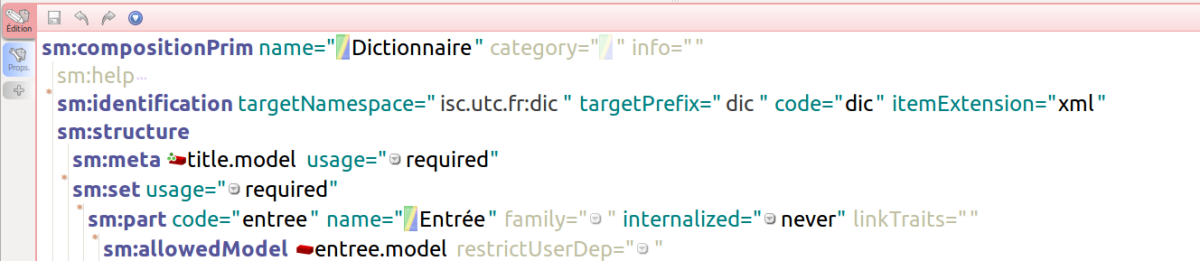
Les différentes primitives sont rédigées dans SCENARIbuilder, l'environnement de modélisation et de génération des modèles documentaires (figures 15 et 16).
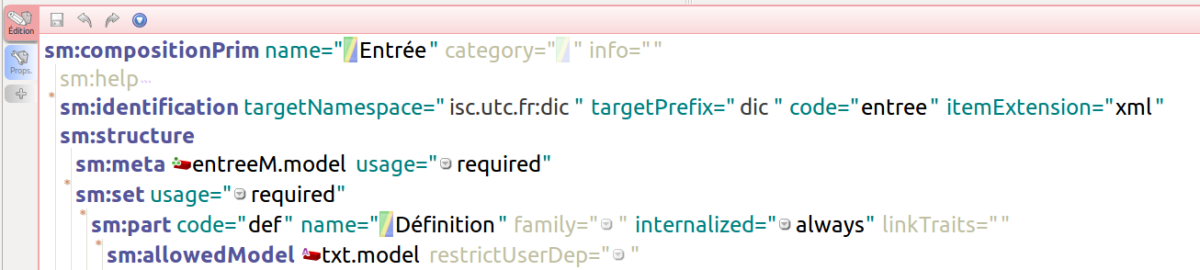
Une fois transformé par SCENARIbuilder et interprété par SCENARIchain, le modèle permet l’instanciation de fragments dictionnaire et de fragments entrée (figures 17 et 18).